Gradle project master --- dependencies
by Walter Xie
We will use the Phylonco project as an example, to learn how to setup project dependencies, and understand the difference between consumers and producers.
1. phylonco-lphy
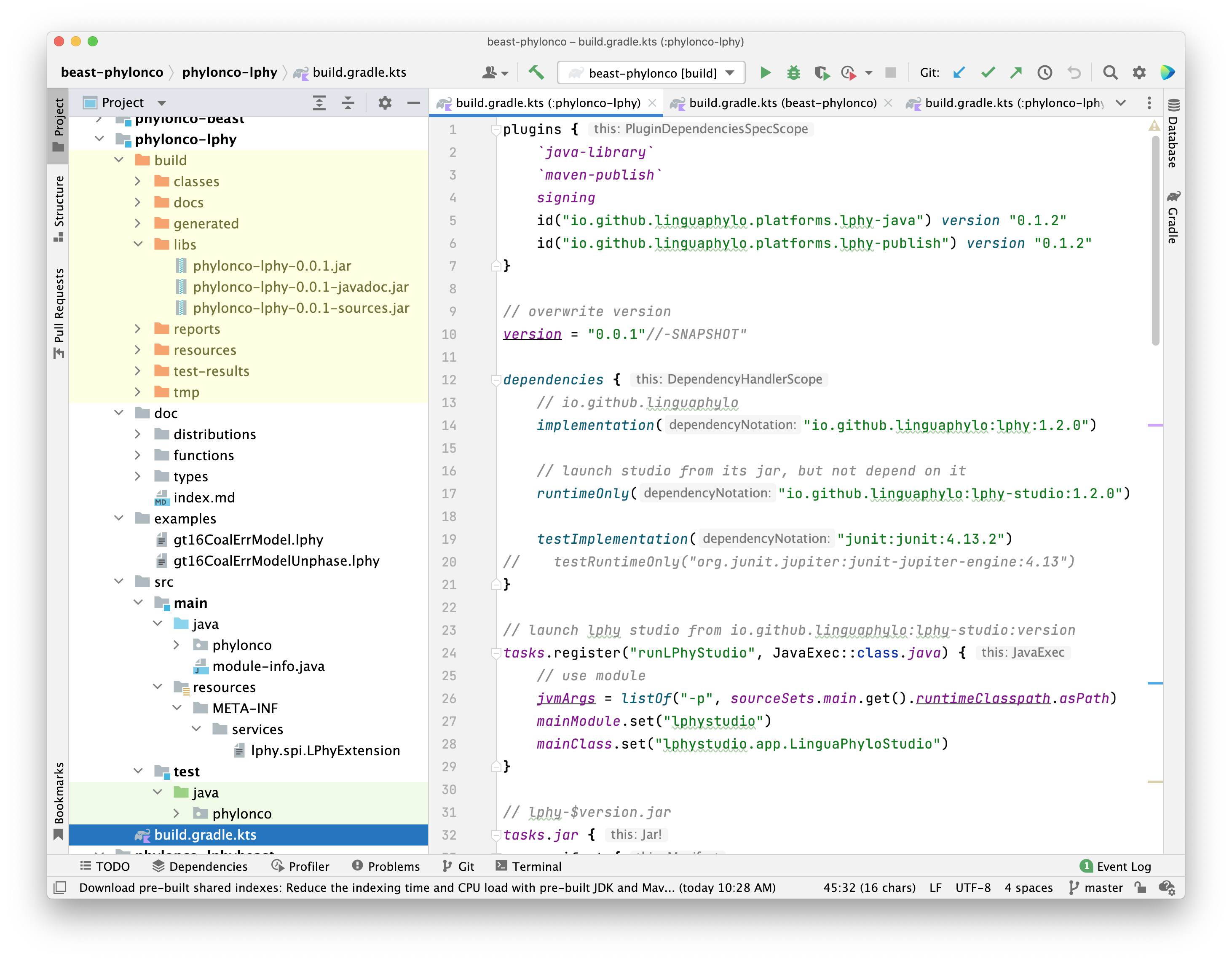
After the version and base name are defined, the second block declares the
dependencies.
The first dependency is lphy module.
The implementation is a Gradle pre-defined
configuration
to resolve dependencies.
The string inside implementation defines GAV coordinate (Group, Artifact, Version),
which will map to a unique corresponding version of a software from all releases.
It also can be used as a keyword to search in the Maven central repo, for example,
the group io.github.linguaphylo.
We use the default model “require”
declaring versions, such as io.github.linguaphylo:lphy:1.3.1.
This implies that the selected version of lphy cannot be lower than 1.3.1
but could be higher through conflict resolution, when there are multiple versions in the local dependency repository.
When the exact version is required, the “strictly”
declaring versions can be used.
For example, if only lphy 1.2.0 is required, you can use io.github.linguaphylo:lphy:1.2.0!!.
The second dependency is lphy-studio module, because we want to run the studio from this project.
But it certainly should not be required by the code, which has no GUI extension.
So, the runtimeOnly configuration is used.
The third dependency is only used for unit tests.
Using module dependencies, you do not have to worry about any manual process to load the dependency tree of lphy module. They will be automatically downloaded into your Gradle local repository when you first build, according to the dependencies declared in the pom.xml created by publishing task.
Updating your dependencies is important. IntelliJ provides a nice UI for the Gradle project to manage the dependencies.
2. phylonco-beast
The BEAST 2 and its packages are not using the GAV and Maven central repo mechanism, so that we have to use the file dependencies to host their dependencies in Gradle. In order to recognise the version, we rename the released BEAST 2 jars into a format similar with GAV, where the package name follows the version.
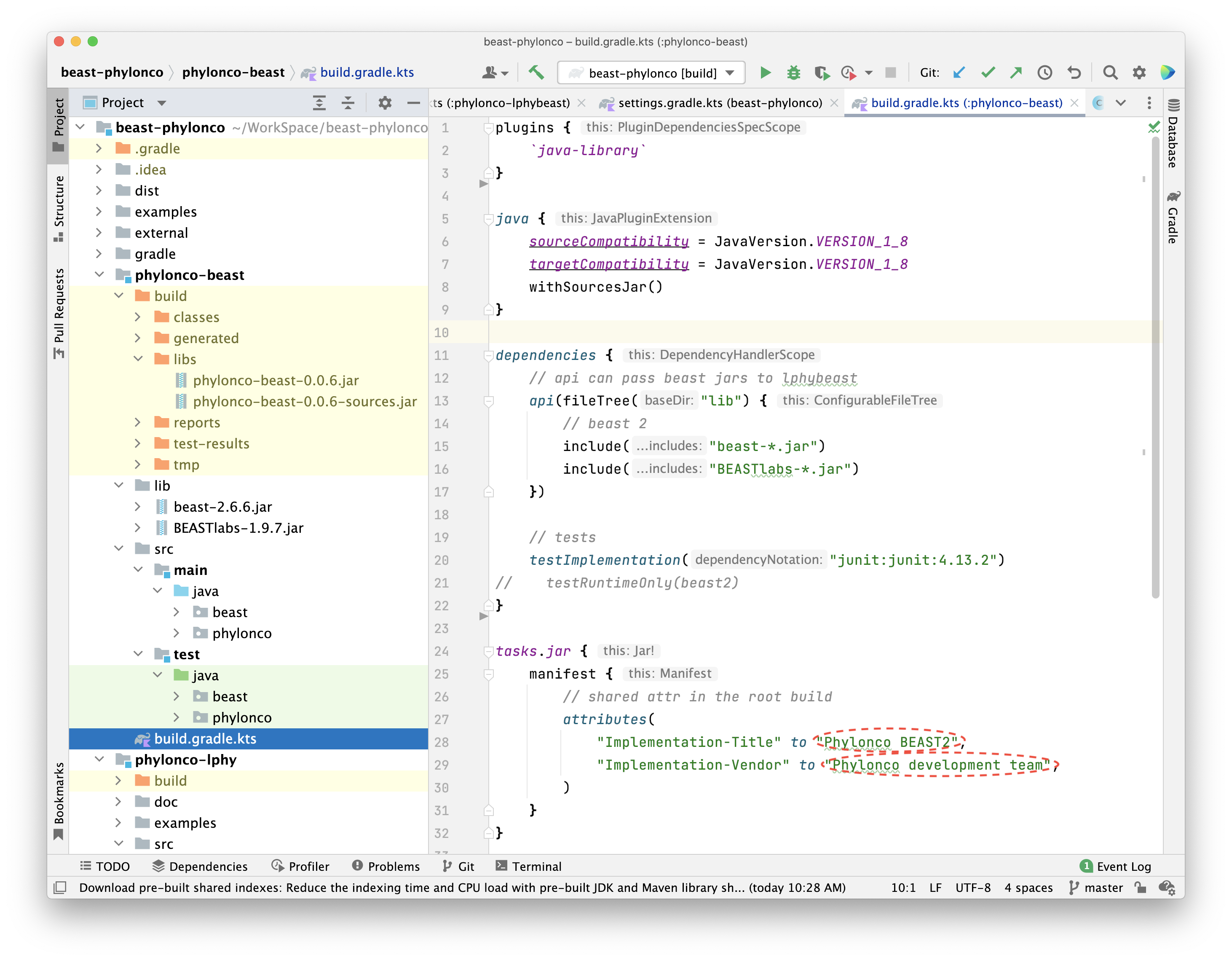
As you can see in Figure 3, this BEAST 2 extension depends on
the jar files of BEAST 2 core and BEASTLabs.
fileTree is used to load the jar files from the given directory as
file dependencies.
The api configuration
is declared for BEAST 2 and BEASTLabs, which means these 2 jars will be exposed to consumers,
which means, for instance, the dependencies of subproject “phylonco-lphybeast” has already included these 2 jars,
because it depends on this subproject.
So, we do not have to replicate jars in the “phylonco-lphybeast” lib folder.
But please use api wisely and
be respectful of consumers.
The list of available BEAST 2 packages and their package dependencies can be seen from Package Viewer or Package Manager. If you change the drop-down list from the default XML into “packages-extra.xml” in Package Viewer, you can find the webpage to list both “lphybeast” package and “Phylonco” package. Alternatively, you can find the BEAST 2 package dependencies from the version.xml.
3. phylonco-lphybeast
This subproject integrates all LPhy components and BEAST 2 components, so its dependencies must include LPhy and its extension, BEAST 2 and its extensions, LPhyBEAST core, and all of their dependencies.
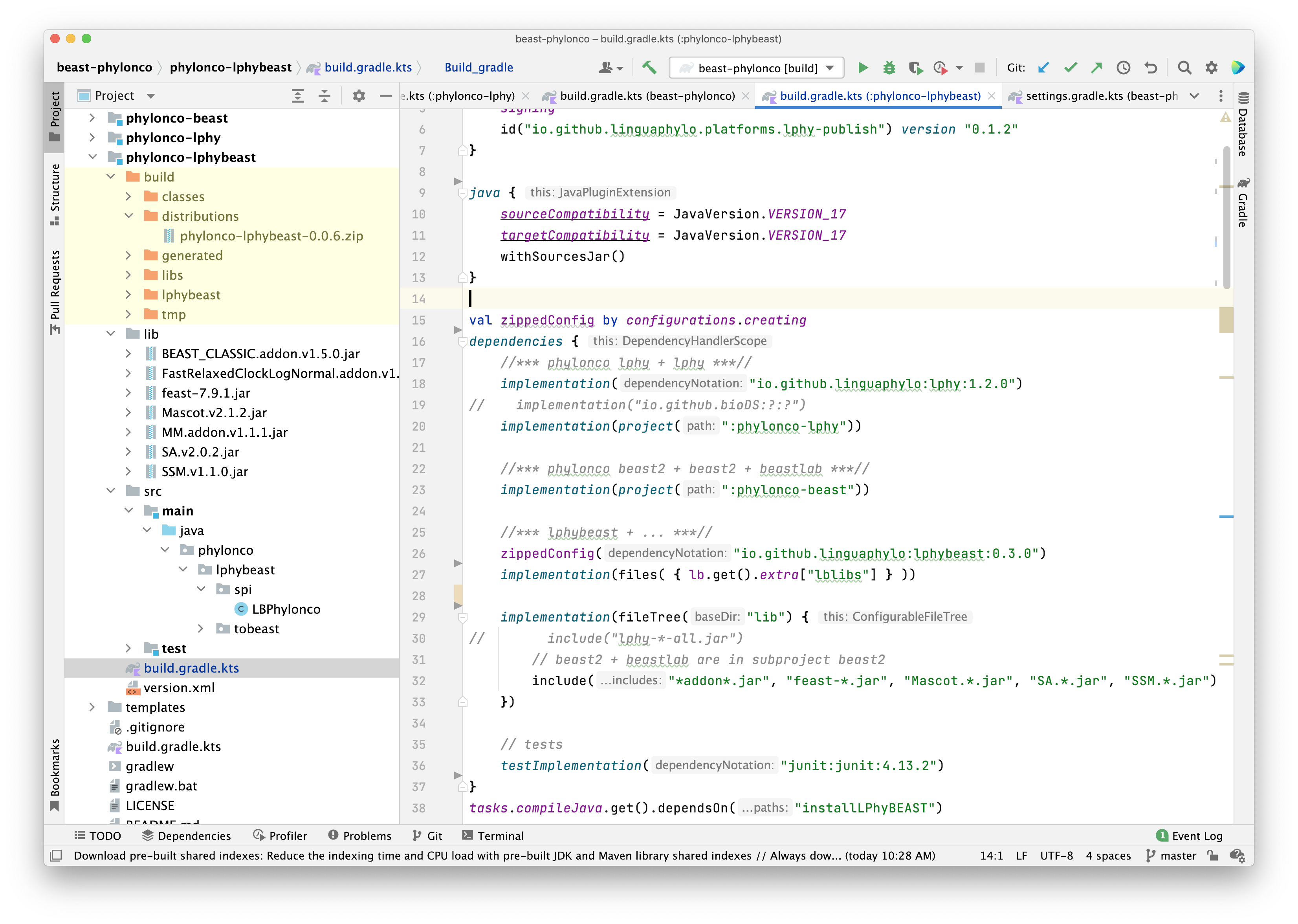
In Figure 4, the first implementation uses GAV to import the LPhy core into the dependencies.
The second loads the module “phylonco-lphy”, which is the LPhy extension, as
project dependencies.
We recommend to always use GAV if possible, but at the time of writing,
“phylonco-lphy” has not been published to the Maven central repo yet.
The third implementation loads the module “phylonco-beast”. Referring to the section 2,
we defined the BEAST 2’s and BEASTLabs’ dependency configuration type as api.
Therefore, this project dependences (project(":phylonco-beast")) include these two jars.
Moreover, the last implementation imports the rest of required BEAST 2 libraries from the lib folder.
In the middle, there is a
custom configuration
zippedConfig to import LPhyBEAST core into the dependencies.
It is a zip file, so we have to use another task named as installLPhyBEAST to unzip it,
and pass all of jar file names in its lib folder into a Gradle property “lblibs”.
Then, the next implementation loads all jar file names stored in “lblibs”.
You can find all these jars from the External Libraries in IntelliJ’s project view.
Understanding your role
Producers and consumers are introduced by the dependency management with Gradle. We strongly recommend you read the linked article to understand the roles.
Please note project dependencies across different repositories are absolutely discouraged by Gradle, due to the encapsulation. This also helps to distinguish the responsibilities of producers and consumers. The producer has the responsibility to provide the reliable version of the software, and use the transitive dependency wisely. It is the consumer’s responsibility to decide what version of the library to use. The consumers should always consume the released or published version, not the latest version of the repository. But a snapshot version built from the latest code can be used only for an emergency situation or testing. This principle allows the developer in a consumer role to focus on one version to develop or extend, so as to produce a stable version of his software.
So the developers cannot load multiple projects (repositories) into the same window of IntelliJ anymore, even though one depends on another project. Therefore, for convenience of consumers, the producer has to provide the source code during the release.
Gradle alos introduces a useful feature, the variant model, which allows a producer creates different releases using the same source code for different kinds of consumers.